Model Notes
Model 4: DistilBERT (Hugging Face Endpoint + Redis)
This is the production model. DistilBERT is fine-tuned for sentiment classification and deployed on Hugging Face Inference Endpoints.
Redis is layered on top as a caching layer: users instantly see cached results (stale up to 1h old) while new predictions are fetched in the background.
There's also a /warm route to pre-heat the endpoint to reduce cold-start latency.
Scores are normalized to the same [-1, 1] range as earlier models, so the front end doesn't need changes. Accuracy and general performance are way stronger than earlier setups, and it's scalable enough for a web demo.
To do: experiment with larger Reddit-specific fine-tuning datasets, optimize Hugging Face instance costs, maybe add smarter eviction rules for Redis cache.
Model 3: PyTorch LSTM
Instead of pooling, this model used an LSTM, a type of RNN designed to capture sequential context across word sequences. This was an improvement because word order matters a lot in sentiment (e.g., "not good" vs "good"). More computationally intensive but captured more complex dependencies.
Optimization
At first, training accuracy increased and validation loss decreased until ~epoch 3. After that, validation loss went up even as training accuracy climbed, which is textbook overfitting. Increasing vocabulary size (from 4k → 30k-50k) massively helped, pushing validation accuracy to ~89% at epoch 6 before overfitting. Still, inference latency made it hard to serve in real-time.
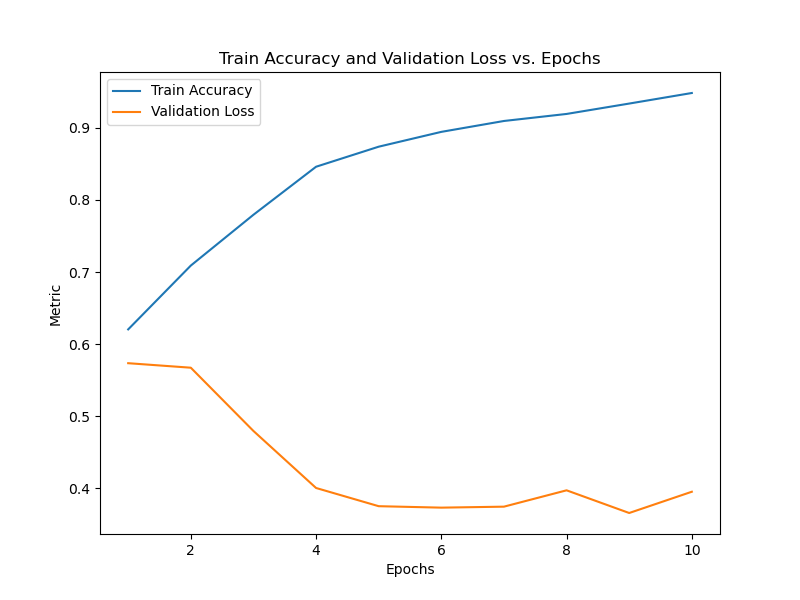
Sample run:
Epoch 1/10, Train Acc: 0.6205, Val Loss: 0.5736
Epoch 2/10, Train Acc: 0.7090, Val Loss: 0.5674
Epoch 3/10, Train Acc: 0.7794, Val Loss: 0.4797
Epoch 4/10, Train Acc: 0.8460, Val Loss: 0.4006
Epoch 5/10, Train Acc: 0.8739, Val Loss: 0.3753
Epoch 6/10, Train Acc: 0.8944, Val Loss: 0.3733
Epoch 7/10, Train Acc: 0.9095, Val Loss: 0.3747
Epoch 8/10, Train Acc: 0.9193, Val Loss: 0.3974
Epoch 9/10, Train Acc: 0.9336, Val Loss: 0.3659
Epoch 10/10, Train Acc: 0.9483, Val Loss: 0.3954
I planned more optimizer tuning and cross-validation runs, but honestly: LSTMs are slow, so I shelved it for production.
Model 2: Keras Neural Network
This model used an Embedding layer and a shallow Dense neural net. It was a step up from Naive Bayes since embeddings encode semantic meaning, but it ignored sequential context. For example, “not good” and “good not” collapsed into the same embedding vector, which is obviously wrong. Dropout helped with overfitting but overall performance plateaued quickly.
Model 1: Naive Bayes (TextBlob)
The very first prototype. TextBlob’s Naive Bayes sentiment classifier was used because it was light and easy to deploy. It just counted words (“stupid” = negative, “great” = positive), but assumed independence. So “pretty stupid” = pretty + stupid instead of context. Worked for a quick demo, but way too naive to be accurate.